Insight
What is Insight? Insight is a program that helps academics and other highly skilled individuals to transition into other, data related fields. It consists of a 7 week session in which the Insight fellows work on building their own projects, interview preparation and improving their coding skills. The projects are then presented to industry representatives to give the fellows a direct introduction to companies and their hiring teams. For my Insight Data Engineering project I developed an ETL pipeline for a platform that lets users compare different ride-share options.
Introduction
Ride-share providers like Lyft and Uber are getting more and more popular. As the market grows, more ride-share and mobility providers join this trend. Ride-share users want to be able to compare different providers according to their current needs without checking each and every app. Whether they need their ride to arrive fast or be cheap, Ride-Share-Compare will give users all the information to make an informed decision.
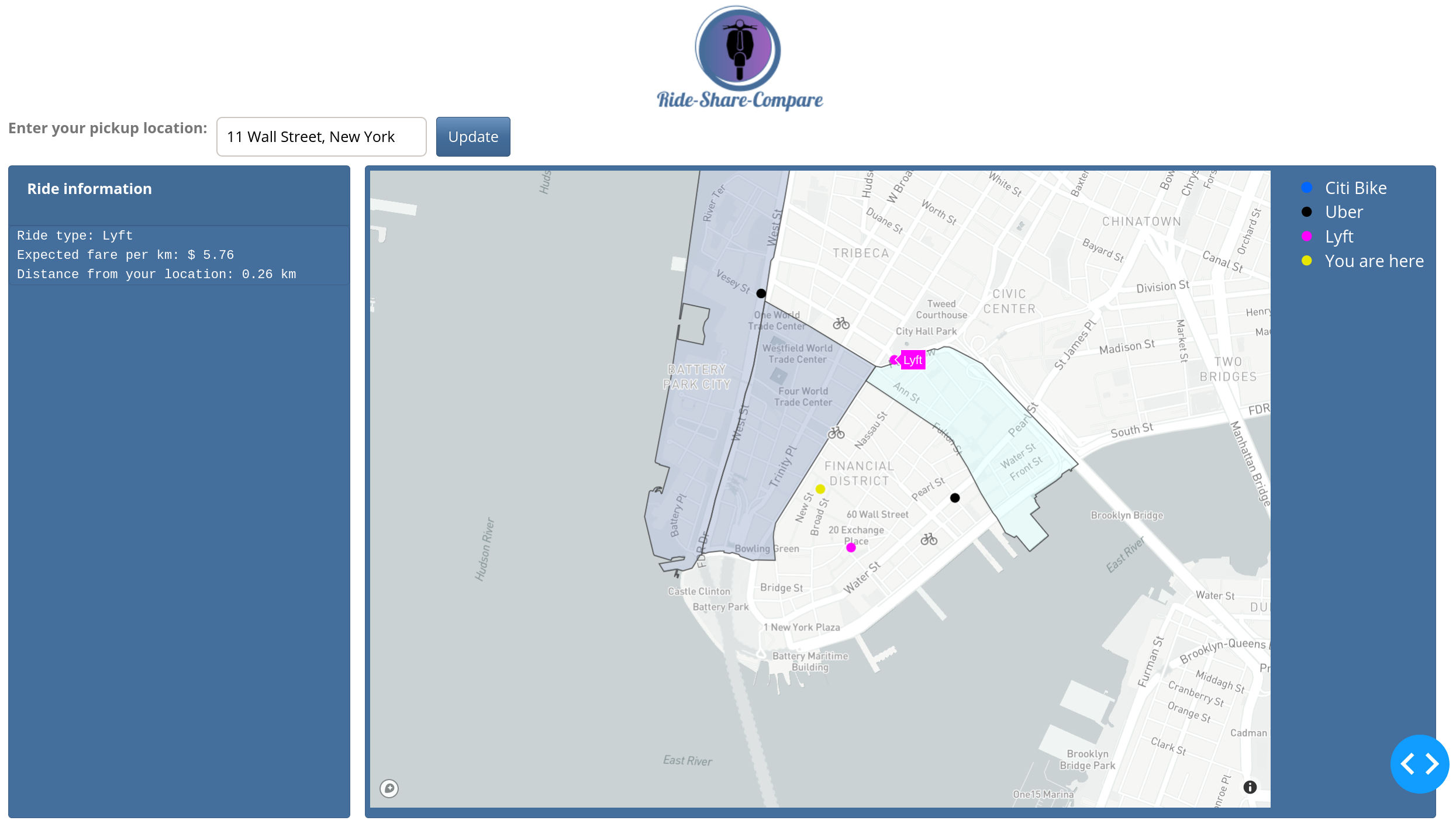
The Ride-Share-Compare user interface allows the user the enter their pickup location. The closest available rides are then displayed around the user’s location. Unfortunately, the data does not provide the ride’s current locations, only the pick-up and drop-off locations. Therefore, available rides here means are all rides that had a recent drop-off close to the user location. Selecting individual rides shows additional information about the expected fare per distance and the distance of the ride from the user’s location. The expected fare is calculated as the fare per distance from the previous ride and the distance of the ride from the user’s location is the straight line connecting the two points.
The data used for this project was the New York City taxi dataset, since real ride-share data is hard to come by. The dataset is published by the NYC Taxi and Limousine Commission (TLC). The data is also available on Amazon S3 as a public dataset. Using a pre-existing dataset instead of real-time data also allows for the simulation of an evolving data schema (see below for more information). In addition, New York Citi Bike data is used to add more variety to the data and available rides. This data is published by Citi Bike.
Early NYC taxi data provided the taxi location in the form of geographical coordinates. Therefore, these rides are displayed as colored dots on the map. Newer taxi data only provides a location ID that corresponds to a neighborhood. Therefore, for the newer taxi data, instead of showing a dot on the map, the neighborhood in which the ride currently is is highlighted and a mouse-over reveals the number of available rides in that neighborhood. Further, Citi Bike data is displayed as bicycles on the map. The locations correspond to the location of the bike station where the bike has been last dropped off.
Architecture
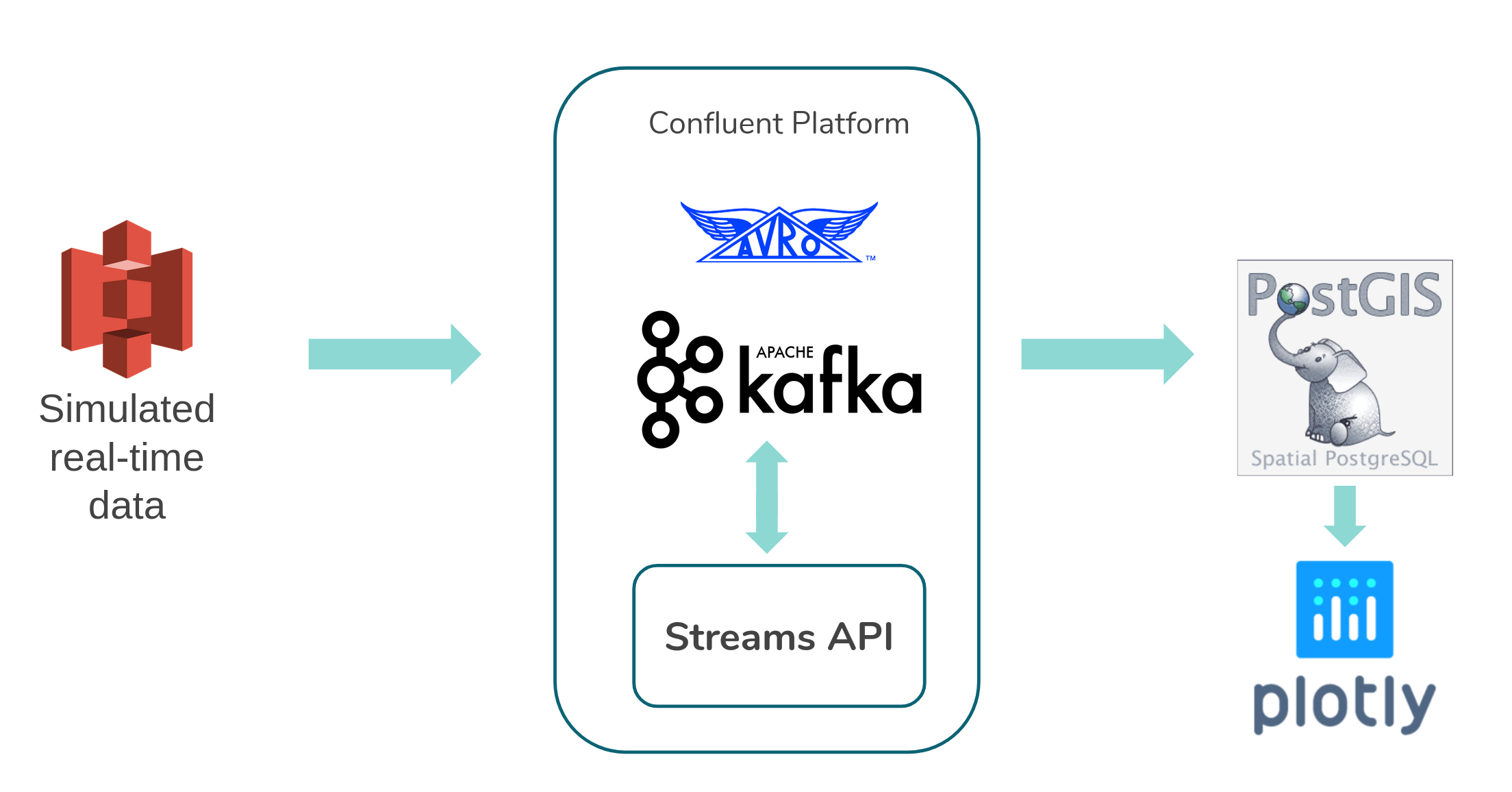
The data resides in a Amazon S3 bucket from where it is streamed into Apache Kafka. A Confluent Kafka cluster is set up on 4 Amazon EC2 nodes. The cluster consists of 4 Zookeepers and Kafka Brokers. In addition, a schema registry is configured that handles the evolution of the data schema. Avro is chosen as a serialization format to work with the schema registry. The ride-share data evolves over time. New versions of the Kafka applications account for the change in the data’s schema. In order to not cause downtime of the pipeline, the update to newer code versions needs to happen during production time. Confluent Kafka uses a schema registry that allows the evolution of the data schema. Adding default values to the data schema allows for full backward and forward compatibility between old and new versions of the Kafka applications. These versions can then run in simultaneously and process and consume messages of all schema versions.
A PostGIS server resides on an additional EC2 node. PostGIS was chosen to allow for geographic queries of the ride locations. This allows to filter the data by proximity of a users position. A trade-off had to be made here since only one PostGIS database is used for storing the data. This is sufficient for storing the amount of incoming data in this test version. For an increasing number of ride-share providers and when including locations other than just New York City the database will not be able to handle the input. In this case the data should most likely not be stored in a SQL database like PostGIS for permanent storage, but rather saved in a NoSQL database.
The Plotly Dash web application is hosted on another EC2 node. Dash was chosen since it easily integrates Mapbox. Custom Mapbox layers display the different New York City neighborhoods used in later versions of the NYC TLC dataset. Geocoding of the user’s address is done by a simple call to the OpenStreetMap geocoder API.
Schema evolution
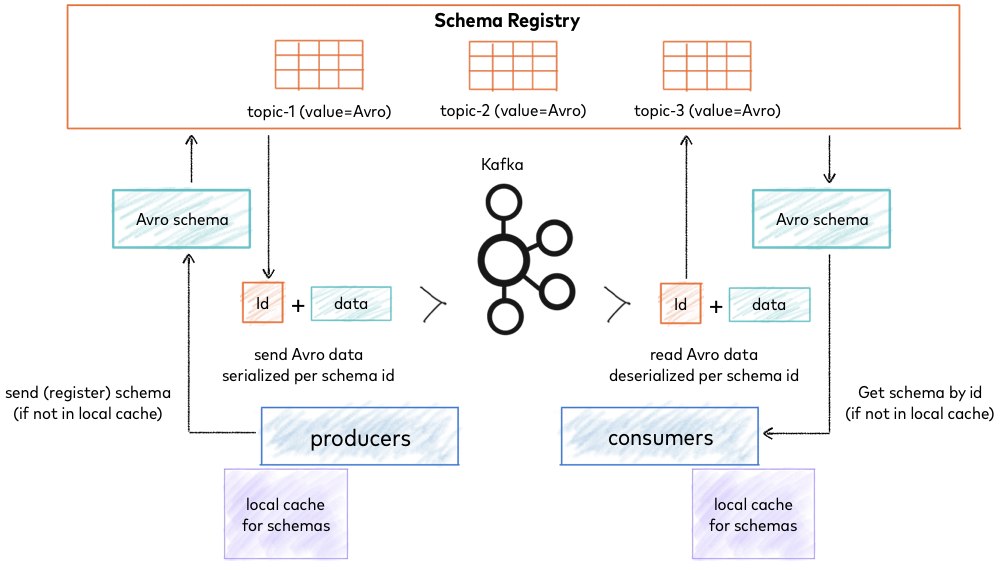 In a streaming application the incoming data might evolve over time. For example, early versions of the ride-share data might include a field
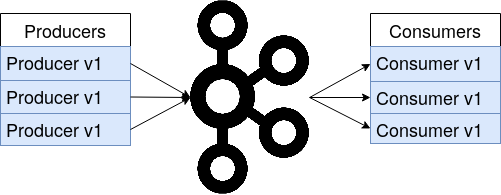
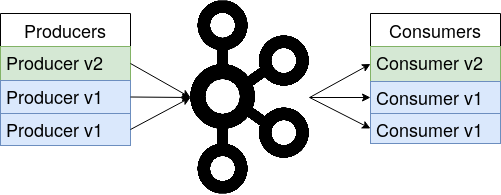
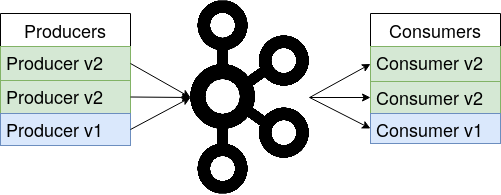
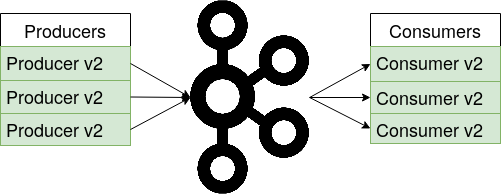
In a streaming application the incoming data might evolve over time. For example, early versions of the ride-share data might include a field fare for the ride’s fare amount. In later versions of the data the fare amount might be sub-divided into a base fare and surcharge amount. If a new version of a Kafka consumer that was written for the later data schema tries to read data from the earlier schema, this consumer shouldn’t break because it is missing the two additional fields. For this reason, the Confluent Schema Registry is used, which stores all versions of a schema and the Kafka applications can pull the correct schema version that corresponds to the message’s data they currently process, as shown in the figure on the right (and Confluent website). For full forward and backward compatibility, all fields in the schema need to have a default value. Then, if e.g. a consumer gets data from a schema version that misses a field the consumer expects, it can simply use the default value. Deploying a Kafka cluster with a fully forward and backward compatible schema registry allows for a rolling deployment of the pipeline. If a new schema version comes in, all Kafka applications can be gradually updated on the fly as shown in the images below. Due to the full compatibility mode, both old and new versions of the Kafka producers and consumers can run in parallel, processing data from different schema versions. This assures that the pipeline stays online during updates and all services remain available to the users.
Check out the project on github.