
PlayerUnknown’s Battlegrounds is currently one of the most popular Battle Royal type shooters with Millions of players worldwide. This popularity also means that there is a huge amount of data available. The data used in the Kaggle kernel competition ‘PUBG Finish Placement Prediction’ consisted of match statistics data taken from the official PUBG API. The goal of the competition was to predict the label winPlacePerc, that is the percentage rank a player or team achieved in a match. The features were basic game stats such as kills, heals, walkDistance, damageDealt, and so on.
Since the percentage rank is defined for a individual match, my idea was to train a neural net incrementally, one match at a time, and then make the predictions in the same way. The scikit-learn framework provides a multi-layer perceptron (MLP) regressor
sklearn.neural_network.MLPRegressor
which can be trained incrementally my calling the method
partial_fit(x_train, y_train)
To feed the data to the model, a few modifications were in order. For one, the data was divided in different match types, defined by the features matchType. Available match types were solo, duo team and crash, where the first three types correspond to the size of the teams in a match (1 player, two players or four player) and the last type is a special event type of match where player do not use fire arms, but instead use melee weapons and vehicles to kill each other. Of course not all features were equally important in all match types, e.g. the feature revives had little impact on the winPlacePerc in the solo player matches. The respective features were then removed in the data set of that specific match type.
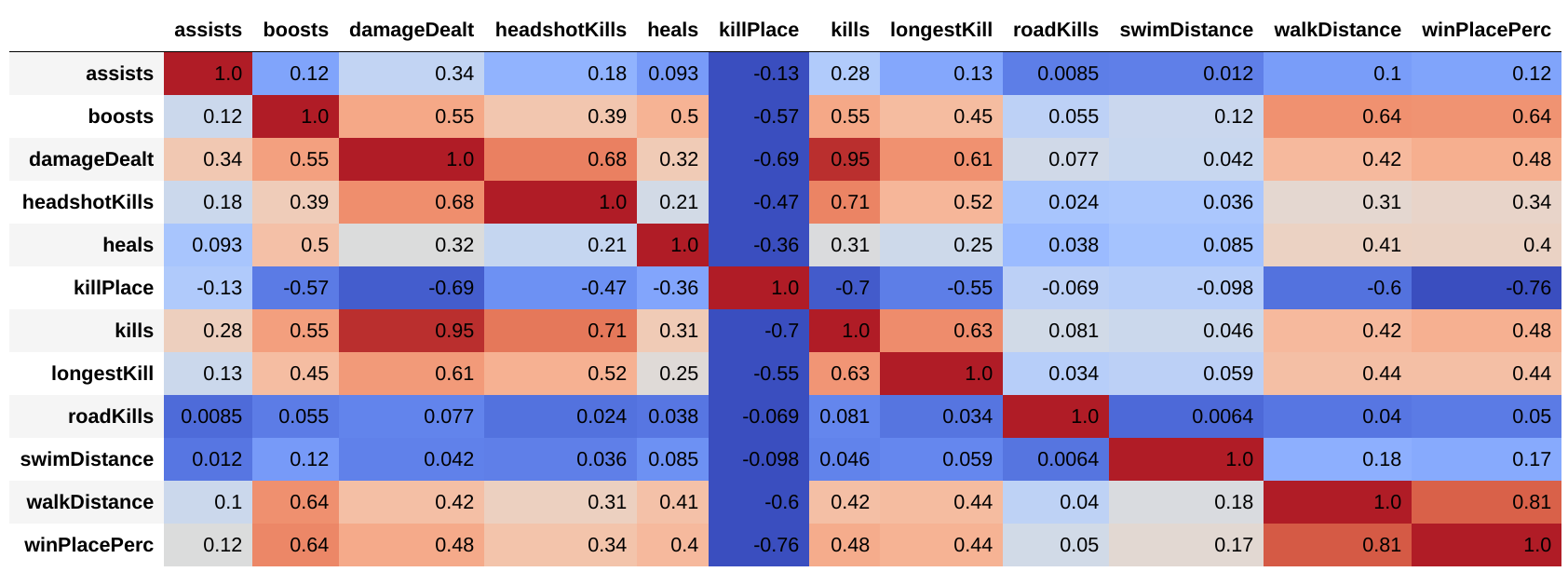 Once the data was sorted according to the match type, the features needed to be transformed into a form the MLP regressor can handle. In the first step, I reduced the number of features. The data set contains many numerical features, so my idea was to use a PCA analysis to get the main components and only fit on those. However, the partial fit method in the MLP regressor has a bug that prevented me from reducing the number of components. Therefore I chose to manually remove in each match type the features that had the least correlation with
Once the data was sorted according to the match type, the features needed to be transformed into a form the MLP regressor can handle. In the first step, I reduced the number of features. The data set contains many numerical features, so my idea was to use a PCA analysis to get the main components and only fit on those. However, the partial fit method in the MLP regressor has a bug that prevented me from reducing the number of components. Therefore I chose to manually remove in each match type the features that had the least correlation with winPlacePerc and use PCA on the remaining ones. Finally, since I used a neural net, the data needed scaled. For this I chose the sk-learnMinMaxScaler. In the picture you can see a sample of the correlation matrix for the solo matches. As you can see, the feature roadKills has only a tiny correlation with winPlacePerc and is therefore removed. Large correlation, and therefore large impact on the winPlacePerc came from the features boosts, killPlace and walkDistance. At first glance walk distance does not seem very important for winning. However, once you realize that walk distance is also correlated to the time a player stayed in a match, it’s clear that players that had large walk distances survived for longer and were therefore placed higher in the final score.
In the last step before the training, I filtered out all matches that had a total of only one or two player. The reason is, that the outcome of these matches can be predicted ‘manually’. Matches with only one player automatically assign the player a winPlacePerc of 0.0. For matches with a total of two player, the player with a lower killPlace had a winPlacePerc of 1.0 in 99% of the training samples.
The remaining matches were then fed into the neural net. To evaluate the performance, I used a k-fold type cross validation on random subsets of the training data. The resulting evaluation mean absolute error was 0.06078. Compared to the Kernel’s Public Score of 0.05489, it did a bit better on the test data, than it did on the training data.
Check out my Kaggle Kernel to get the details.